Go concurrency applied to data pipelines
Go 并发应用于数据管道
一种不同的批处理方法,以及如何在使用 Go 并发模型的过程中增强数据管道的功能。
1.Introduction to pipelines
管道简介
应用于计算机科学领域的术语 ——管道 无非是一系列阶段,这些阶段接收数据,对该数据执行一些操作,并将处理后的数据作为结果传回。
接收数据—— 处理数据—— 返回数据
因此,在使用这种模式时
-
可以通过添加/删除/修改阶段来封装每个阶段的逻辑并快速扩展功能
- 每个阶段都变得易于测试
- 更不必说通过使用并发来利用这个的巨大的好处
想象一下,有机会在一家食品和 CPG 配送公司担任软件工程师,在那里是一个团队的一员,负责构建软件,将零售商的产品可用性集成到主公司的应用程序中。运行该集成后,用户能够以更少的缺货风险购买产品。
-
为了完成这个功能,怎么 GoLang 中构建了这个“可用性引擎”呢?
-
这个“可用性引擎”要怎么实现?
-
这个“可用性引擎”要实现什么功能?
// 1.应该提取了几个零售商的 CSV 文件,其中包含产品可用性信息 // 2.执行几个步骤来根据某些业务逻辑来丰富和过滤数据 // 3.流程结束后应该制作一个新的文件 // 4.所有的产品都将集成到公司的应用程序中供用户购买。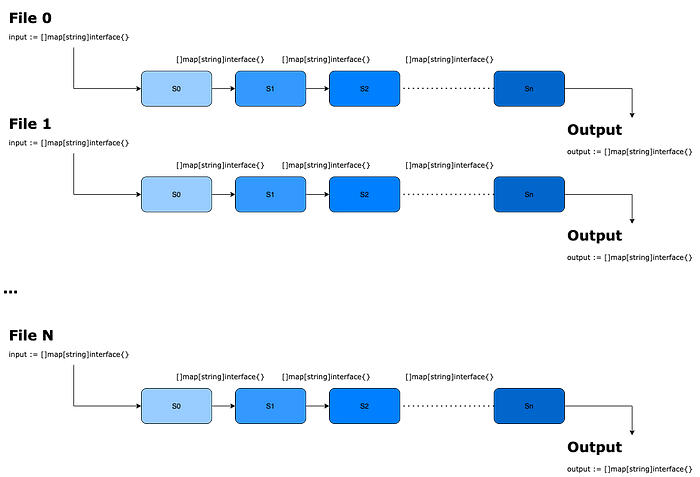
批量处理架构示例
- 管道的第一阶段接收一组 CSV 行,将它们全部处理,然后将结果放入新批次(新的地图切片)中。
- 相同的过程重复它的次数与管道实际具有的阶段数一样多,这种模式的特殊性在于,如果管道中的上一步尚未完成对整组行的处理,则下一个阶段都无法开始。如所见,它在概念上是一个批处理管道。
- 为了加快和优化工作,我们开始在 CSV 文件级别使用并发,因此我们能够同时处理文件。这种方法非常适合我们,但没有我们常说的灵丹妙药……
- 我偶然发现了一种奇妙的模式,即通过使用通道来利用管道!!!!!!!!!!
2.A better approach for data pipelines: streams of data
更好的数据管道方法:数据流
在阶段之间使用批处理,这对我们来说已经足够了,但肯定还有其他选项更适合使其更高效。
特别是我们谈论的是跨不同管道阶段的流数据。这实际上意味着每个阶段一次接收和发出一个元素,而不是等待上一步的一整批结果来处理它们。
- 如果我们必须比较批处理和流式处理之间的内存占用,前者更大,因为每个阶段都必须制作一个新的等长映射切片来存储其计算结果。
- 相反,流式处理方法最终会一次接收和发送一个元素,因此内存占用量会降低到管道输入的大小
Implementation example
实现示例
// 第一阶段stream.UserIDs(done, userIDs...)将通过流式传输UserIDs值来为管道提供数据
package stream
//为了实现这一点,使用了一个生成器模式,它接收一个UserID切片(输入),并通过对其进行测距,开始将每个值推入一个通道(输出)。因此,返回的通道将依次成为下一阶段的输入。
type UserID uint
func UserIDs(done <-chan interface{}, uids ...UserID) <-chan UserID {
uidStream := make(chan UserID)
go func() {
defer close(uidStream)
for v := range uids {
select {
case <-done:
return
case uidStream <- UserID(v):
fmt.Printf("[In func UserIDs] UserID %v has been push in Stream Channel\n", v)
}
}
}()
return uidStream
}
正因为如此,跨管道使用通道将允许我们安全地同时执行每个管道阶段,因为我们的输入和输出在并发上下文中是安全的。
让我们看一下链上的以下阶段,其中基于来自第一阶段(生成器)的流数据,我们获取实际的用户数据,过滤掉不活跃的用户,用其配置文件丰富他们,最后将一些数据拆分为从整个聚合/过滤过程中制作一个普通对象。
// 获取用户并在频道上返回他们
type User struct {
ID UserID
Username string
Email string
IsActive bool
}
func UserInput(done <-chan interface{}, uids <-chan UserID) <-chan User {
stream := make(chan User)
go func() {
defer close(stream)
for v := range uids {
user, err := getUser(v)
if err != nil {
fmt.Println("some error ocurred", err)
} else {
select {
case <-done:
fmt.Println("[case done ] return ")
return
case stream <- user:
fmt.Printf("[In func UserInput] UserID %#v has been push in Stream Channel\n", v)
default:
fmt.Println("channel blocking")
}
}
}
}()
return stream
}
// getUser 是一个虚拟的函数 用来模拟在处理数据时,对不同的数据进行不同的操作。
func getUser(ID UserID) (User, error) {
username := fmt.Sprintf("username_%v", ID)
user := User{
ID: ID,
Username: username,
Email: fmt.Sprintf("%v@pipeliner.com"),
IsActive: true,
}
if ID%3 == 0 {
user.IsActive = false
}
return user, nil
}
// 过滤掉不活跃的用户
func InactiveUsers(done <-chan interface{}, users <-chan User) <-chan User {
stream := make(chan User)
go func() {
defer close(stream)
for v := range users {
if v.IsActive == false {
fmt.Printf("[In func InactiveUsers] %#v has been filtered", v)
continue
}
select {
case <-done:
fmt.Println("[case done ] return ")
return
case stream <- v:
fmt.Printf("[In func InactiveUsers] User %#v has been push in Stream Channel\n", v)
}
}
}()
return stream
}
type ProfileID uint
//将用户的配置文件聚合到有效负载
//定义一个配置文件
type Profile struct {
ID ProfileID
PhotoURL string
}
//将配置文件和用户聚合在一起
type UserProfileAggregation struct {
User User
Profile Profile
}
type PlainStruct struct {
UserID UserID
ProfileID ProfileID
Username string
PhotoURL string
}
func ProfileInput(done <-chan interface{}, users <-chan User) <-chan UserProfileAggregation {
stream := make(chan UserProfileAggregation)
go func() {
defer close(stream)
for v := range users {
profile, err := getByUserID(v.ID)
if err != nil {
// TODO address errors in a better way
fmt.Println("some error ocurred")
p := UserProfileAggregation{
User: v,
Profile: profile}
select {
case <-done:
return
case stream <- p:
fmt.Println("[In func Profile] UserProfileAggregation has been inputed in channel")
}
}
}
}()
return stream
}
func getByUserID(uids UserID) (Profile, error) {
p := Profile{
ID: ProfileID(uint(uids) + 100),
PhotoURL: fmt.Sprintf("https://some-storage-url/%v-photo", uids),
}
return p, nil
}
//将有效负载转换为它的简化版本
func UPAggToPlainStruct(done <-chan interface{}, upAggToPlainStruct <-chan UserProfileAggregation) <-chan PlainStruct {
stream := make(chan PlainStruct)
go func() {
defer close(stream)
for v := range upAggToPlainStruct {
p := v.ToPlainStruct()
select {
case <-done:
return
case stream <- p:
fmt.Println("[In func UPAggToPlainStruct ] PlainStruct has been pushed into channel")
}
}
}()
return stream
}
func (upa UserProfileAggregation) ToPlainStruct() PlainStruct {
return PlainStruct{
UserID: upa.User.ID,
ProfileID: upa.Profile.ID,
Username: upa.User.Username,
PhotoURL: upa.Profile.PhotoURL,
}
}
const maxUserID = 100
func main() {
done := make(chan interface{})
defer close(done)
userIDs := make([]UserID, maxUserID)
for i := 1; i <= maxUserID; i++ {
userIDs = append(userIDs, UserID(i))
}
arg1 := UserInput(
done,
UserIDs(done, userIDs...),
)
arg2 := InactiveUsers(
done,
arg1,
)
arg3 := ProfileInput(
done,
arg2,
)
plainStructs := UPAggToPlainStruct(done, arg3)
for ps := range plainStructs {
fmt.Printf("[result] plain struct for UserID %v is: -> %v \n", ps.UserID, ps)
}
}
我在各个阶段传递了一个done chan 接口{} 。这个是来做什么的?值得一提的是,goroutines 在运行时不会被垃圾回收,所以作为程序员,我们必须确保它们都是可抢占的。因此,通过这样做,我们不会泄漏任何 goroutine(我将在稍后的另一篇文章中写更多关于此的内容)并释放内存。因此,只要关闭done通道,就可以停止对管道的任何调用。这个动作将导致所有 spawn children 的 goroutines 的终止并清理它们。
总而言之,在管道上的最新阶段之后,开始通过其输出通道将数据推出另一个例程.
简而言之,如果我有机会解决与以前类似的问题,我肯定会采用这种模式,它不仅在内存占用方面性能更高,而且速度比使用批处理方法,因为我们可以同时处理数据。
此外,我们还可以对管道进行许多其他操作,例如速率限制和扇入/扇出。这个主题将在后面继续学习,其想法是通过添加和组合更多的并发模式来不断迭代这个模式。