什么是 Distributed Tracing(分布式跟踪)?
在微服务的世界中,大多数问题是由于网络问题和不同微服务之间的关系而发生的。分布式架构(相对于单体架构)使得找到问题的根源变得更加困难。要解决这些问题,我们需要查看哪个服务向另一个服务或组件(数据库、队列等)发送了哪些参数。分布式跟踪通过使我们能够从系统的不同部分收集数据来帮助我们实现这一目标,从而使我们的系统能够实现这种所需的可观察性。
- 分布式跟踪使我们从系统的不同部分收集数据从而找到问题的根源。
- 此外,trace 是一种可视化工具,可以让我们将系统可视化以更好地了解服务之间的关系,从而更容易调查和查明问题
1.什么是 Jaeger 追踪?
Jaeger 是 Uber 在 2015 年创建的开源分布式跟踪平台。它由检测 SDK、用于数据收集和存储的后端、用于可视化数据的 UI 以及用于聚合跟踪分析的 Spark/Flink 框架组成。
Jaeger 数据模型与 OpenTracing 兼容,OpenTracing 是一种规范,用于定义收集的跟踪数据的外观,以及不同语言的实现库(稍后将详细介绍 OpenTracing 和 OpenTelemetry)。
与大多数其他分布式跟踪系统一样,Jaeger 使用spans and traces,如 OpenTracing 规范中定义的那样。
span 代表应用程序中的一个工作单元(HTTP 请求、对 DB 的调用等),是 Jaeger 最基本的工作单元。Span必须具有操作名称、开始时间和持续时间。
Traces 是以父/子关系连接的跨度的集合/列表(也可以被认为是Span的有向无环图)。Traces 指定如何通过我们的服务和其他组件传播请求。
2.Jaeger 追踪架构
它由几个部分组成,我将在下面解释所有这些部分:
-
Instrumentation SDK:集成到应用程序和框架中以捕获跟踪数据的库。从历史上看,Jaeger 项目支持使用各种编程语言编写的自己的客户端库。它们现在被弃用,取而代之的是 OpenTelemetry(同样,稍后会详细介绍)。
- Jaeger 代理: Jaeger 代理是一个网络守护程序,用于侦听通过 UDP 从 Jaeger 客户端接收到的跨度。它收集成批的它们,然后将它们一起发送给收集器。如果 SDK 被配置为将 span 直接发送到收集器,则不需要代理。
- Jaeger 收集器: Jaeger 收集器负责从 Jaeger 代理接收跟踪,执行验证和转换,并将它们保存到选定的存储后端。
- 存储后端: Jaeger 支持各种存储后端来存储跨度。支持的存储后端有 In-Memory、Cassandra、Elasticsearch 和 Badger(用于单实例收集器部署)。
- Jaeger Query:这是一项服务,负责从 Jaeger 存储后端检索跟踪信息,并使其可供 Jaeger UI 访问。
- Jaeger UI:一个 React 应用程序,可让您可视化跟踪并分析它们。对于调试系统问题很有用。
- Ingester:只有当我们使用 Kafka 作为收集器和存储后端之间的缓冲区时,ingester 才有意义。它负责从 Kafka 接收数据并将其摄取到存储后端。更多信息可以在官方 Jaeger Tracing 文档中找到。
使用 Docker 在本地运行 Jaeger
Jaeger 附带一个即用型一体化Docker 映像,其中包含 Jaeger 运行所需的所有组件。
在本地机器上启动并运行它非常简单:
docker run -d --name jaeger \
-e COLLECTOR_ZIPKIN_HOST_PORT=:9411 \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686: 16686 \
-p 14250:14250 \
-p 14268:14268 \
-p 14269:14269 \
-p 9411:9411 \
jaegertracing/all-in-one:1.30
然后可以简单地在http://localhost:16686上打开 jaeger UI 。
Jaeger 跟踪和 OpenTelemetry
我之前确实提到过 Jaeger 的数据模型与 OpenTracing 规范兼容。可能已经知道 OpenTracing 和 OpenCensus 已合并形成 OpenTelemetry。
SDK 中的采样策略
(弃用的)Jaeger SDK 有 4 种采样模式:
- Remote:默认值,用于告诉 Jaeger SDK 采样策略由 Jaeger 后端控制。
- 常数:要么取所有痕迹,要么不取。中间什么都没有。全部为 1,无为 0
- 速率限制:选择每秒采样的跟踪数。
- 概率:选择将被采样的轨迹的百分比,例如 - 选择 0.1 以使每 10 条轨迹中有 1 条被采样。
远程采样
如果我们选择启用远程采样,Jaeger 收集器将负责确定每个服务中的 SDK 应该使用哪种采样策略。操作员有两种配置收集器的方法:使用采样策略配置文件,或使用自适应采样。
配置文件 — 为收集器提供一个文件路径,该文件包含每个服务和操作前采样配置。
自适应采样——让 Jaeger 了解每个端点接收的流量并计算出该端点最合适的速率。请注意,在撰写本文时,只有 Memory 和 Cassandra 后端支持这一点。
可以在此处找到有关 Jaeger 采样的更多信息:https ://www.jaegertracing.io/docs/latest/sampling/
Jaeger 追踪术语表
Span——我们系统中发生的工作单元(动作/操作)的表示;跨越时间的 HTTP 请求或数据库操作(从 X 开始,持续时间为 Y 毫秒)。通常,它将是另一个跨度的父级和/或子级。
Trace — 表示请求进程的树/跨度列表,因为它由我们系统中的不同服务和组件处理。例如,向 user-service 发送 API 调用会导致对 users-db 的 DB 查询。它们是分布式服务的“调用堆栈”。
Observability可观察性——衡量我们根据外部输出了解系统内部状态的程度。当您拥有日志、指标和跟踪时,您就拥有了“可观察性的 3 个支柱”。
OpenTelemetry — OpenTelemetry 是 CNCF(云原生计算功能)的一个开源项目,它提供了一系列工具、API 和 SDK。OpenTelemetry 支持使用单一规范自动收集和生成跟踪、日志和指标。
OpenTracing — 一个用于分布式跟踪的开源项目。它已被弃用并“合并”到 OpenTelemetry 中。OpenTelemetry 为 OpenTracing 提供向后兼容性。
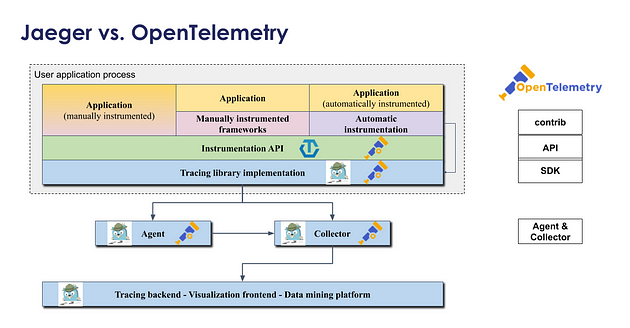
OpenTelemetry 和 Jaeger
与其他一些跟踪后端不同,Jaeger 项目从未打算解决代码检测问题。通过发布与 OpenTracing 兼容的跟踪器库,我们能够利用现有兼容 OpenTracing 的仪器的丰富生态系统,并将我们的精力集中在构建跟踪后端、可视化工具和数据挖掘技术上。
上下文传播作为底层
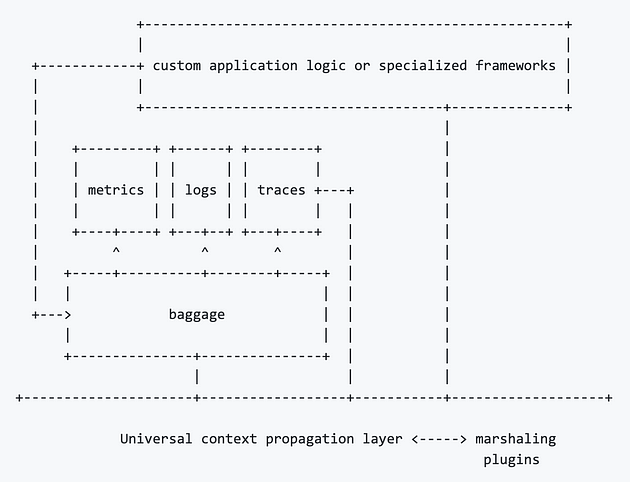
OpenCensus 代理/收集器呢?
即使对于 OpenCensus 库,“包含电池”的方法也并不总是有效,因为它们仍然需要配置特定的导出器插件才能将数据发送到具体的跟踪后端,如 Jaeger 或 Zipkin。为了解决这个问题,OpenCensus 项目开始开发两个称为agent和collector的后端组件,它们扮演着与 Jaeger 的 agent 和 collector 几乎相同的角色:
- 代理是一个边车/主机代理,它以标准化格式从客户端库接收遥测数据并将其转发给收集器;
- 收集器将数据转换为特定跟踪后端可以理解的格式并将其发送到那里。OpenCensus Collector 还能够执行基于尾部的抽样。