关于Metrics, tracing, and logging 的不同
1.metrics
我认为metrics的定义特征是它们是可聚合aggregatable的:它们是在一段时间内组成单个逻辑量规、计数器或直方图的原子。例如:队列的当前深度可以建模为一个计量器,其更新与 last-writer-win 语义聚合;传入的 HTTP 请求的数量可以建模为一个计数器,其更新通过简单的加法聚合;并且观察到的请求持续时间可以建模为直方图,其更新聚合到时间桶中并产生统计摘要。
2.logging
我认logging 的定义特征是它处理离散事件。例如:应用程序调试或错误消息通过logs实例发送到 终端或者文件流输出。审计跟踪audit-trail事件通过 Kafka 推送到 BigTable 等数据湖;或从服务调用中提取的特定于请求的元数据并发送到像 NewRelic 这样的错误跟踪服务。
3. tracking
我认为 tracking 的唯一定义特征是它处理请求范围内的信息。可以绑定到系统中单个事务对象的生命周期的任何数据或元数据。例如:出站 RPC 到远程服务的持续时间;发送到数据库的实际 SQL 查询的文本;或入站 HTTP 请求的相关 ID。
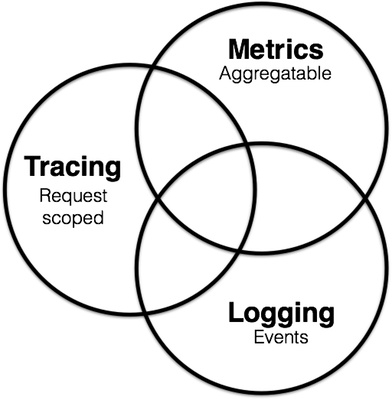
通过这些定义,我们可以标记重叠部分。
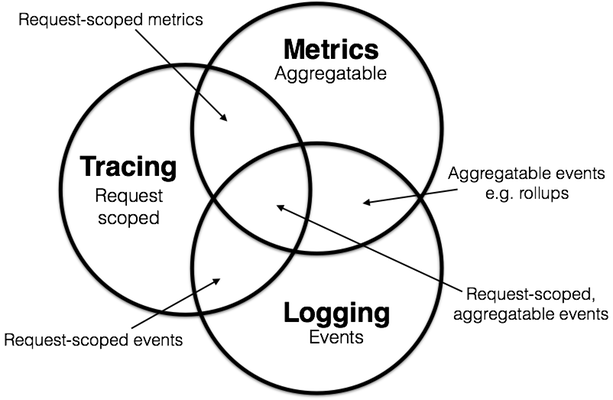
当然,云原生应用程序的许多典型工具最终都将是请求范围的,因此在更广泛的跟踪上下文中讨论可能是有意义的。但是我们现在可以观察到,并非所有仪器都绑定到请求生命周期:例如逻辑组件诊断信息或流程生命周期细节,它们与任何离散请求正交。因此,例如,并非所有指标或日志都可以硬塞到跟踪系统中——至少,不是没有一些工作。或者,我们可能会意识到直接在我们的应用程序中检测指标会给我们带来强大的好处,比如]prometheus.io/docs/querying/basics估我们车队的实时视图;相比之下,将指标硬塞到日志管道中可能会迫使我们放弃其中的一些优势。
此外,我观察到一个奇怪的操作细节作为这种可视化的副作用。在这三个领域中,metrics往往需要最少的资源来管理,因为它们的本质是“压缩”得很好。相反,logging往往是压倒性的,经常超过它报告的生产流量。tracking可能位于中间的某个位置。