通过Exporter收集指标
Exporter介绍
Exporter 是一个采集监控数据并通过 Prometheus 监控规范对外提供数据的组件,它负责从目标系统(Your 服务)搜集数据,并将其转化为 Prometheus 支持的格式。Prometheus 会周期性地调用 Exporter 提供的 metrics 数据接口来获取数据。那么使用 Exporter 的好处是什么?举例来说,如果要监控 Mysql/Redis 等数据库,我们必须要调用它们的接口来获取信息(前提要有),这样每家都有一套接口,这样非常不通用。所以 Prometheus 做法是每个软件做一个 Exporter,Prometheus 的 Http 读取 Exporter 的信息(将监控指标进行统一的格式化并暴露出来)。简单类比,Exporter 就是个翻译,把各种语言翻译成一种统一的语言。
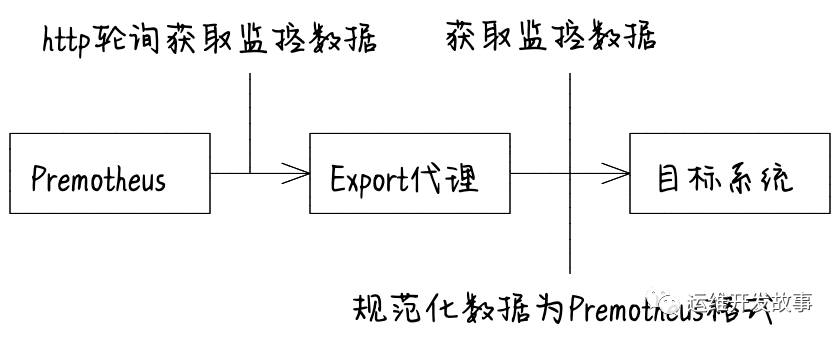
对于Exporter而言,它的功能主要就是将数据周期性地从监控对象中取出来进行加工,然后将数据规范化后通过端点暴露给Prometheus,所以主要包含如下3个功能。
- 封装功能模块获取监控系统内部的统计信息。
- 将返回数据进行规范化映射,使其成为符合Prometheus要求的格式化数据。
- Collect模块负责存储规范化后的数据,最后当Prometheus定时从Exporter提取数据时,Exporter就将Collector收集的数据通过HTTP的形式在/metrics端点进行暴露。
Primetheus client
golang client 是当pro收集所监控的系统的数据时,用于响应pro的请求,按照一定的格式给pro返回数据,说白了就是一个http server。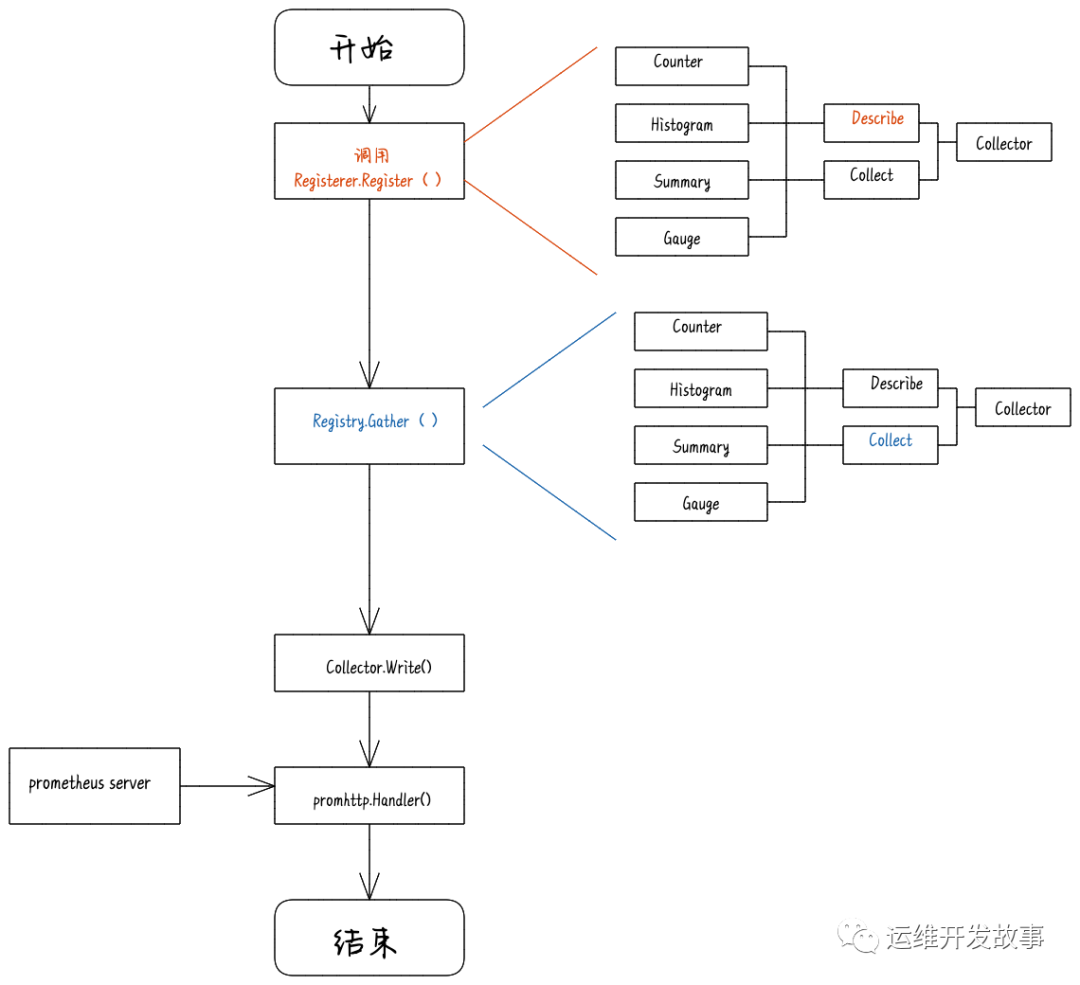
数据类型
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0.5"} 0.000107458
go_gc_duration_seconds{quantile="0.75"} 0.000200112
go_gc_duration_seconds{quantile="1"} 0.000299278
go_gc_duration_seconds_sum 0.002341738
go_gc_duration_seconds_count 18
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 107
这些信息有一个共同点,就是采用了不同于JSON或者Protocol Buffers的数据组织形式——文本形式。在文本形式中,每个指标都占用一行,#HELP代表指标的注释信息,#TYPE用于定义样本的类型注释信息,紧随其后的语句就是具体的监控指标(即样本)。#HELP的内容格式如下所示,需要填入指标名称及相应的说明信息。
HELP <metrics_name> <doc_string>
#TYPE的内容格式如下所示,需要填入指标名称和指标类型(如果没有明确的指标类型,需要返回untyped)。
TYPE <metrics_name> <metrics_type>
监控样本部分需要满足如下格式规范。
metric_name [ "{" label_name "=" " label_value " { "," label_name "=" " label_value " } [ "," ] "}" ] value [ timestamp ]
其中,metric_name和label_name必须遵循PromQL的格式规范。value是一个f loat格式的数据,timestamp的类型为int64(从1970-01-01 00:00:00开始至今的总毫秒数),可设置其默认为当前时间。具有相同metric_name的样本必须按照一个组的形式排列,并且每一行必须是唯一的指标名称和标签键值对组合。
- Counter:Counter是一个累加的数据类型。一个Counter类型的指标只会随着时间逐渐递增(当系统重启的时候,Counter指标会被重置为0)。记录系统完成的总任务数量、系统从最近一次启动到目前为止发生的总错误数等场景都适合使用Counter类型的指标。
- Gauge:Gauge指标主要用于记录一个瞬时值,这个指标可以增加也可以减少,比如CPU的使用情况、内存使用量以及硬盘当前的空间容量等。
- Histogram:Histogram表示柱状图,主要用于统计一些数据分布的情况,可以计算在一定范围内的数据分布情况,同时还提供了指标值的总和。在大多数情况下,用户会使用某些指标的平均值作为参考,例如,使用系统的平均响应时间来衡量系统的响应能力。这种方式有个明显的问题——如果大多数请求的响应时间都维持在100ms内,而个别请求的响应时间需要1s甚至更久,那么响应时间的平均值体现不出响应时间中的尖刺,这就是所谓的“长尾问题”。为了更加真实地反映系统响应能力,常用的方式是按照请求延迟的范围进行分组,例如在上述示例中,可以分别统计响应时间在[0,100ms]、[100,1s]和[1s,∞]这3个区间的请求数,通过查看这3个分区中请求量的分布,就可以比较客观地分析出系统的响应能力。
- Summary:Summary与Histogram类似,也会统计指标的总数(以_count作为后缀)以及sum值(以_sum作为后缀)。两者的主要区别在于,Histogram指标直接记录了在不同区间内样本的个数,而Summary类型则由客户端计算对应的分位数。例如下面展示了一个Summary类型的指标,其中quantile=”0.5”表示中位数,quantile=”0.9”表示九分位数。
广义上讲,所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter,Exporter的一个实例被称为target,Prometheus会通过轮询的形式定期从这些target中获取样本数据。
动手编写一个Exporter
package main
import (
"log"
"net/http"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
cpuTemp = prometheus.NewGauge(prometheus.GaugeOpts{
NameSpace: "our_idc",
Subsystem: "k8s"
Name: "cpu_temperature_celsius",
Help: "Current temperature of the CPU.",
})
hdFailures = prometheus.NewCounterVec(
prometheus.CounterOpts{
NameSpace: "our_idc",
Subsystem: "k8s"
Name: "hd_errors_total",
Help: "Number of hard-disk errors.",
},
[]string{"device"},
)
)
func init() {
// Metrics have to be registered to be exposed:
prometheus.MustRegister(cpuTemp)
prometheus.MustRegister(hdFailures)
}
func main() {
cpuTemp.Set(65.3)
hdFailures.With(prometheus.Labels{"device":"/dev/sda"}).Inc()
// The Handler function provides a default handler to expose metrics
// via an HTTP server. "/metrics" is the usual endpoint for that.
http.Handle("/metrics", promhttp.Handler())
log.Fatal(http.ListenAndServe(":8888", nil))
}
CounterVec是用来管理相同metric下不同label的一组CountercounterVec是有label的,而单纯的gauage对象却不用lable标识,这就是基本数据类型和对应Vec版本的差别.
自定义Collector
直接使用Collector,go client Colletor只会在每次响应Prometheus请求的时候才收集数据。需要每次显式传递变量的值,否则就不会再维持该变量,在Prometheus也将看不到这个变量。Collector是一个接口,所有收集metrics数据的对象都需要实现这个接口,Counter和Gauage等不例外。它内部提供了两个函数,Collector用于收集用户数据,将收集好的数据传递给传入参数Channel就可;Descirbe函数用于描述这个Collector。
package main
import (
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
"net/http"
"sync"
)
type ClusterManager struct {
sync.Mutex
Zone string
metricMapCounters map[string]string
metricMapGauges map[string]string
}
//Simulate prepare the data
func (c *ClusterManager) ReallyExpensiveAssessmentOfTheSystemState() (
metrics map[string]float64,
) {
metrics = map[string]float64{
"oom_crashes_total": 42.00,
"ram_usage": 6.023e23,
}
return
}
//通过NewClusterManager方法创建结构体及对应的指标信息,代码如下所示。
// NewClusterManager creates the two Descs OOMCountDesc and RAMUsageDesc. Note
// that the zone is set as a ConstLabel. (It's different in each instance of the
// ClusterManager, but constant over the lifetime of an instance.) Then there is
// a variable label "host", since we want to partition the collected metrics by
// host. Since all Descs created in this way are consistent across instances,
// with a guaranteed distinction by the "zone" label, we can register different
// ClusterManager instances with the same registry.
func NewClusterManager(zone string) *ClusterManager {
return &ClusterManager{
Zone: zone,
metricMapGauges: map[string]string{
"ram_usage": "ram_usage",
},
metricMapCounters: map[string]string{
"oom_crashes": "oom_crashes_total",
},
}
}
func (c *ClusterManager) Describe(ch chan<- *prometheus.Desc) {
// prometheus.NewDesc(prometheus.BuildFQName(namespace, "", metricName), docString, labels, nil)
for _, v := range c.metricMapGauges {
ch <- prometheus.NewDesc(prometheus.BuildFQName(c.Zone, "", v), v, nil, nil)
}
for _, v := range c.metricMapCounters {
ch <- prometheus.NewDesc(prometheus.BuildFQName(c.Zone, "", v), v, nil, nil)
}
}
//Collect方法是核心,它会抓取需要的所有数据,根据需求对其进行分析,然后将指标发送回客户端库。
// 用于传递所有可能指标的定义描述符
// 可以在程序运行期间添加新的描述,收集新的指标信息
// 重复的描述符将被忽略。两个不同的Collector不要设置相同的描述符
func (c *ClusterManager) Collect(ch chan<- prometheus.Metric) {
c.Lock()
defer c.Unlock()
m := c.ReallyExpensiveAssessmentOfTheSystemState()
for k, v := range m {
t := prometheus.GaugeValue
if c.metricMapCounters[k] != "" {
t = prometheus.CounterValue
}
c.registerConstMetric(ch, k, v, t)
}
}
// 用于传递所有可能指标的定义描述符给指标
func (c *ClusterManager) registerConstMetric(ch chan<- prometheus.Metric, metric string, val float64, valType prometheus.ValueType, labelValues ...string) {
descr := prometheus.NewDesc(prometheus.BuildFQName(c.Zone, "", metric), metric, nil, nil)
if m, err := prometheus.NewConstMetric(descr, valType, val, labelValues...); err == nil {
ch <- m
}
}
func main() {
workerCA := NewClusterManager("xiaodian")
reg := prometheus.NewPedanticRegistry()
reg.MustRegister(workerCA)
//当promhttp.Handler()被执行时,所有metric被序列化输出。题外话,其实输出的格式既可以是plain text,也可以是protocol Buffers。
http.Handle("/metrics", promhttp.HandlerFor(reg, promhttp.HandlerOpts{}))
http.ListenAndServe(":8888", nil)
}
高质量Exporter的编写原则与方法
- 在访问Exporter的主页(即http://yourExporter/这样的根路径)时,它会返回一个简单的页面,这就是Exporter的落地页(Landing Page)。落地页中可以放文档和帮助信息,包括监控指标项的说明。落地页上还包括最近执行的检查列表、列表的状态以及调试信息,这对故障排查非常有帮助。
- 一台服务器或者容器上可能会有许多Exporter和Prometheus组件,它们都有自己的端口号。因此,在写Exporter和发布Exporter之前,需要检查新添加的端口是否已经被使用[1],建议使用默认端口分配范围之外的端口。
- 我们应该根据业务类型设计好指标的#HELP#TYPE的格式。这些指标往往是可配置的,包括默认开启的指标和默认关闭的指标。这是因为大部分指标并不会真正被用到,设计过多的指标不仅会消耗不必要的资源,还会影响整体的性能。
- 对于如何写高质量Exporter,除了合理分配端口号、设计落地页、梳理指标这3个方面外,还有一些其他的原则。
- 记录Exporter本身的运行状态指标。
- 可配置化进行功能的启用和关闭。
- 推荐使用YAML作为配置格式。
- 遵循度量标准命名的最佳实践[2],特别是_count、_sum、_total、_bucket和info等问题。
- 为度量提供正确的单位。
- 标签的唯一性、可读性及必要的冗余信息设计。
- 通过Docker等方式一键配置Exporter。
- 尽量使用Collectors方式收集指标,如Go语言中的MustNewConstMetric。
- 提供scrapes刮擦失败的错误设计,这有助于性能调试。
- 尽量不要重复提供已有的指标,如Node Exporter已经提供的CPU、磁盘等信息。
- 向Prometheus公开原始的度量数据,不建议自行计算,Exporter的核心是采集原始指标。