go和Web
1.Web开发
因为 Go 的
net/http包提供了基础的路由函数组合与丰富的功能函数。所以在社区里流行一种用 Go 编写 API 不需要框架的观点,在我们看来,如果的项目的路由在个位数、URI 固定且不通过 URI 来传递参数,那么确实使用官方库也就足够。但在复杂场景下,官方的 http 库还是有些力有不逮。例如下面这样的路由:
> GET /card/:id > POST /card/:id > DELTE /card/:id > GET /card/:id/name > GET /card/:id/relations
Go 的 Web 框架大致可以分为这么两类:
-
Router 框架
-
MVC 类框架
在框架的选择上,大多数情况下都是依照个人的喜好和公司的技术栈。例如公司有很多技术人员是 PHP 出身,那么他们一定会非常喜欢像 beego 这样的框架,但如果公司有很多 C 程序员,那么他们的想法可能是越简单越好。比如很多大厂的 C 程序员甚至可能都会去用 C 语言去写很小的 CGI 程序,他们可能本身并没有什么意愿去学习 MVC 或者更复杂的 Web 框架,他们需要的只是一个非常简单的路由(甚至连路由都不需要,只需要一个基础的 HTTP 协议处理库来帮他省掉没什么意思的体力劳动)。Go 的 net/http 包提供的就是这样的基础功能,写一个简单的 http echo server 只需要 30s。
package main
import (
"net/http"
"io/ioutil"
)
func echo(wr http.ResponseWriter, r *http.Request) {
msg, err := ioutil.ReadAll(r.Body)
if err != nil {
wr.Write([]byte("echo error"))
return
}
writeLen, err := wr.Write(msg)
if err != nil || writeLen != len(msg) {
log.Println(err, "write len:", writeLen)
}
}
func main() {
http.HandleFunc("/", echo)
err := http.ListenAndServe(":8080", nil)
if err != nil {
log.Fatal(err)
}
}
开源社区中一个 Kafka 监控项目中的做法:
//Burrow: http_server.go
func NewHttpServer(app *ApplicationContext) (*HttpServer, error) {
...
server.mux.HandleFunc("/", handleDefault)
server.mux.HandleFunc("/burrow/admin", handleAdmin)
server.mux.Handle("/v2/kafka", appHandler{server.app, handleClusterList})
server.mux.Handle("/v2/kafka/", appHandler{server.app, handleKafka})
server.mux.Handle("/v2/zookeeper", appHandler{server.app, handleClusterList})
...
}
没有使用任何 router 框架,只使用了 `net/http`。只看上面这段代码似乎非常优雅,我们的项目里大概只有这五个简单的 URI,所以我们提供的服务就是下面这个样子:/
/burrow/admin
/v2/kafka
/v2/kafka/
/v2/zookeeper
进 handleKafka() 这个函数一探究竟:
func handleKafka(app *ApplicationContext, w http.ResponseWriter, r *http.Request) (int, string) {
pathParts := strings.Split(r.URL.Path[1:], "/")
if _, ok := app.Config.Kafka[pathParts[2]]; !ok {
return makeErrorResponse(http.StatusNotFound, "cluster not found", w, r)
}
if pathParts[2] == "" {
// Allow a trailing / on requests
return handleClusterList(app, w, r)
}
if (len(pathParts) == 3) || (pathParts[3] == "") {
return handleClusterDetail(app, w, r, pathParts[2])
}
switch pathParts[3] {
case "consumer":
switch {
case r.Method == "DELETE":
switch {
case (len(pathParts) == 5) || (pathParts[5] == ""):
return handleConsumerDrop(app, w, r, pathParts[2], pathParts[4])
default:
return makeErrorResponse(http.StatusMethodNotAllowed, "request method not supported", w, r)
}
case r.Method == "GET":
switch {
case (len(pathParts) == 4) || (pathParts[4] == ""):
return handleConsumerList(app, w, r, pathParts[2])
case (len(pathParts) == 5) || (pathParts[5] == ""):
// Consumer detail - list of consumer streams/hosts? Can be config info later
return makeErrorResponse(http.StatusNotFound, "unknown API call", w, r)
case pathParts[5] == "topic":
switch {
case (len(pathParts) == 6) || (pathParts[6] == ""):
return handleConsumerTopicList(app, w, r, pathParts[2], pathParts[4])
case (len(pathParts) == 7) || (pathParts[7] == ""):
return handleConsumerTopicDetail(app, w, r, pathParts[2], pathParts[4], pathParts[6])
}
case pathParts[5] == "status":
return handleConsumerStatus(app, w, r, pathParts[2], pathParts[4], false)
case pathParts[5] == "lag":
return handleConsumerStatus(app, w, r, pathParts[2], pathParts[4], true)
}
default:
return makeErrorResponse(http.StatusMethodNotAllowed, "request method not supported", w, r)
}
case "topic":
switch {
case r.Method != "GET":
return makeErrorResponse(http.StatusMethodNotAllowed, "request method not supported", w, r)
case (len(pathParts) == 4) || (pathParts[4] == ""):
return handleBrokerTopicList(app, w, r, pathParts[2])
case (len(pathParts) == 5) || (pathParts[5] == ""):
return handleBrokerTopicDetail(app, w, r, pathParts[2], pathParts[4])
}
case "offsets":
// Reserving this endpoint to implement later
return makeErrorResponse(http.StatusNotFound, "unknown API call", w, r)
}
// If we fell through, return a 404
return makeErrorResponse(http.StatusNotFound, "unknown API call", w, r)
}
因为默认的
net/http包中的mux不支持带参数的路由,所以 Burrow 这个项目使用了非常蹩脚的字符串Split和乱七八糟的switch case来达到自己的目的,但却让本来应该很集中的路由管理逻辑变得复杂,散落在系统的各处,难以维护和管理。如果读者细心地看过这些代码之后,可能会发现其它的几个handler函数逻辑上较简单,最复杂的也就是这个handleKafka()。而我们的系统总是从这样微不足道的混乱开始积少成多,最终变得难以收拾。
根据我们的经验,简单地来说,只要的路由带有参数,并且这个项目的 API 数目超过了 10,就尽量不要使用
net/http中默认的路由。在 Go 开源界应用最广泛的 router 是 httpRouter,很多开源的 router 框架都是基于 httpRouter 进行一定程度的改造的成果。关于 httpRouter 路由的原理,会在本章节的 router 一节中进行详细的阐释。
开源界有这么几种框架,第一种是对 httpRouter 进行简单的封装,然后提供定制的中间件和一些简单的小工具集成比如 gin,主打轻量,易学,高性能。第二种是借鉴其它语言的编程风格的一些 MVC 类框架,例如 beego,
2.请求路由
在常见的 Web 框架中,router 是必备的组件。Go 语言圈子里 router 也时常被称为 http 的 multiplexer。在上一节中我们通过对 Burrow 代码的简单学习,已经知道如何用 http 标准库中内置的 mux 来完成简单的路由功能了。如果开发 Web 系统对路径中带参数没什么兴趣的话,用 http 标准库中的 mux 就可以。
RESTful 是几年前刮起的 API 设计风潮,在 RESTful 中除了 GET 和 POST 之外,还使用了 HTTP 协议定义的几种其它的标准化语义。具体包括:
const (
MethodGet = "GET"
MethodHead = "HEAD"
MethodPost = "POST"
MethodPut = "PUT"
MethodPatch = "PATCH" // RFC 5789
MethodDelete = "DELETE"
MethodConnect = "CONNECT"
MethodOptions = "OPTIONS"
MethodTrace = "TRACE"
)
来看看 RESTful 中常见的请求路径:
GET /repos/:owner/:repo/comments/:id/reactions
POST /projects/:project_id/columns
PUT /user/starred/:owner/:repo
DELETE /user/starred/:owner/:repo
RESTful 风格的 API 重度依赖请求路径。会将很多参数放在请求 URI 中。除此之外还会使用很多并不那么常见的 HTTP 状态码
如果我们的系统也想要这样的 URI 设计,使用标准库的 mux 显然就力不从心了。
2.1 httprouter
较流行的开源 go Web 框架大多使用 httprouter,或是基于 httprouter 的变种对路由进行支持。前面提到的 Github 的参数式路由在 httprouter 中都是可以支持的。
因为 httprouter 中使用的是显式匹配,所以在设计路由的时候需要规避一些会导致路由冲突的情况,例如:
conflict:
GET /user/info/:name
GET /user/:id
no conflict:
GET /user/info/:name
POST /user/:id
##简单来讲的话,如果两个路由拥有一致的 http 方法 (指 GET、POST、PUT、DELETE) 和请求路径前缀,且在某个位置出现了 A 路由是 wildcard(指 :id 这种形式)参数,B 路由则是普通字符串,那么就会发生路由冲突。路由冲突会在初始化阶段直接 panic
还有一点需要注意,因为 httprouter 考虑到字典树的深度,在初始化时会对参数的数量进行限制,所以在路由中的参数数目不能超过 255,否则会导致 httprouter 无法识别后续的参数。不过这一点上也不用考虑太多,毕竟 URI 是人设计且给人来看的,相信没有长得夸张的 URI 能在一条路径中带有 200 个以上的参数。
除支持路径中的 wildcard 参数之外,httprouter 还可以支持 * 号来进行通配,不过 * 号开头的参数只能放在路由的结尾,例如下面这样:
Pattern: /src/*filepath
/src/ filepath = ""
/src/somefile.go filepath = "somefile.go"
/src/subdir/somefile.go filepath = "subdir/somefile.go"
这种设计在 RESTful 中可能不太常见,主要是为了能够使用 httprouter 来做简单的 HTTP 静态文件服务器。
除了正常情况下的路由支持,httprouter 也支持对一些特殊情况下的回调函数进行定制,例如 404 的时候:
r := httprouter.New()
r.NotFound = http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("oh no, not found"))
})
内部 panic 的时候:
r.PanicHandler = func(w http.ResponseWriter, r *http.Request, c interface{}) {
log.Printf("Recovering from panic, Reason: %#v", c.(error))
w.WriteHeader(http.StatusInternalServerError)
w.Write([]byte(c.(error).Error()))
}
目前开源界最为流行(star 数最多)的 Web 框架 gin 使用的就是 httprouter 的变种。
2.2 原理
2.2.1
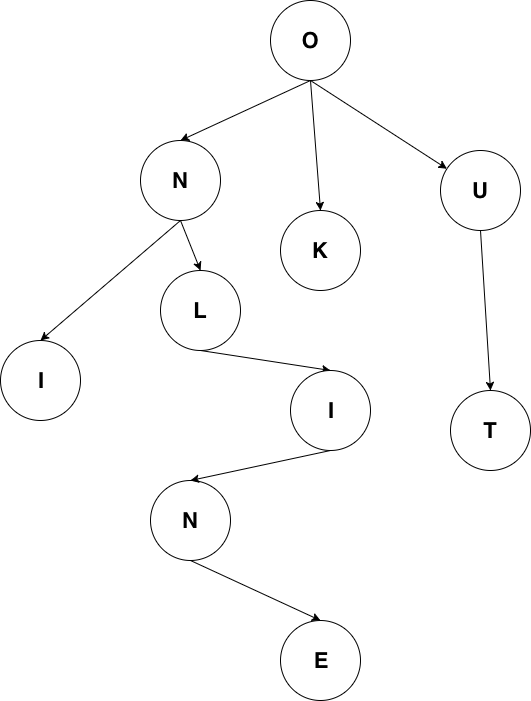
httprouter 和众多衍生 router 使用的数据结构被称为压缩字典树(Radix Tree)。读者可能没有接触过压缩字典树,但对字典树(Trie Tree)应该有所耳闻。图 5-1 是一个典型的字典树结构:
图为字典树
字典树常用来进行字符串检索,例如用给定的字符串序列建立字典树。对于目标字符串,只要从根节点开始深度优先搜索,即可判断出该字符串是否曾经出现过,时间复杂度为 O(n),n 可以认为是目标字符串的长度。为什么要这样做?字符串本身不像数值类型可以进行数值比较,两个字符串对比的时间复杂度取决于字符串长度。如果不用字典树来完成上述功能,要对历史字符串进行排序,再利用二分查找之类的算法去搜索,时间复杂度只高不低。可认为字典树是一种空间换时间的典型做法。
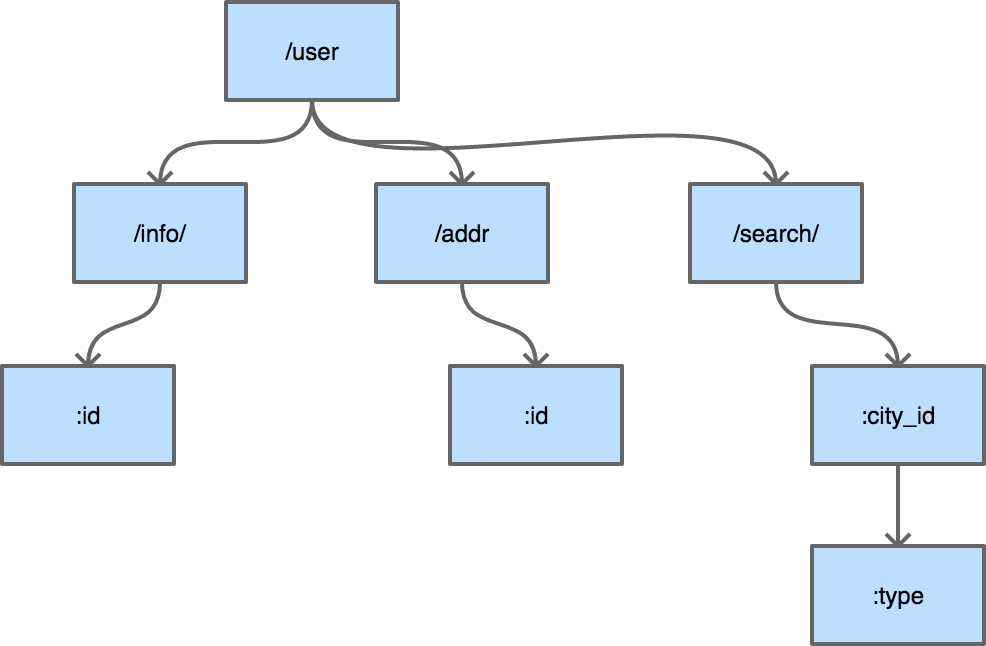
普通的字典树有一个比较明显的缺点,就是每个字母都需要建立一个孩子节点,这样会导致字典树的层数比较深,压缩字典树相对好地平衡了字典树的优点和缺点。是典型的压缩字典树结构:
图为压缩字典树
每个节点上不只存储一个字母了,这也是压缩字典树中 “压缩” 的主要含义。使用压缩字典树可以减少树的层数,同时因为每个节点上数据存储也比通常的字典树要多,所以程序的局部性较好(一个节点的 path 加载到 cache 即可进行多个字符的对比),从而对 CPU 缓存友好。
2.2.2压缩字典树创建过程
我们来跟踪一下 httprouter 中,一个典型的压缩字典树的创建过程,路由设定如下:
PUT /user/installations/:installation_id/repositories/:repository_id
GET /marketplace_listing/plans/
GET /marketplace_listing/plans/:id/accounts
GET /search
GET /status
GET /support
补充路由:
GET /marketplace_listing/plans/ohyes
最后一条补充路由是我们臆想的,除此之外所有 API 路由均来自于 api.github.com
2.2.3 root 节点的创建
// 略去了其它部分的 Router struct
type Router struct{
// ...
trees map[string]*node
// ...
}
trees 中的 key 即为 HTTP 1.1 的 RFC 中定义的各种方法,具体有:
GET
HEAD
OPTIONS
POST
PUT
PATCH
DELETE
每一种方法对应的都是一棵独立的压缩字典树,这些树彼此之间不共享数据。具体到我们上面用到的路由,PUT 和 GET 是两棵树而非一棵。
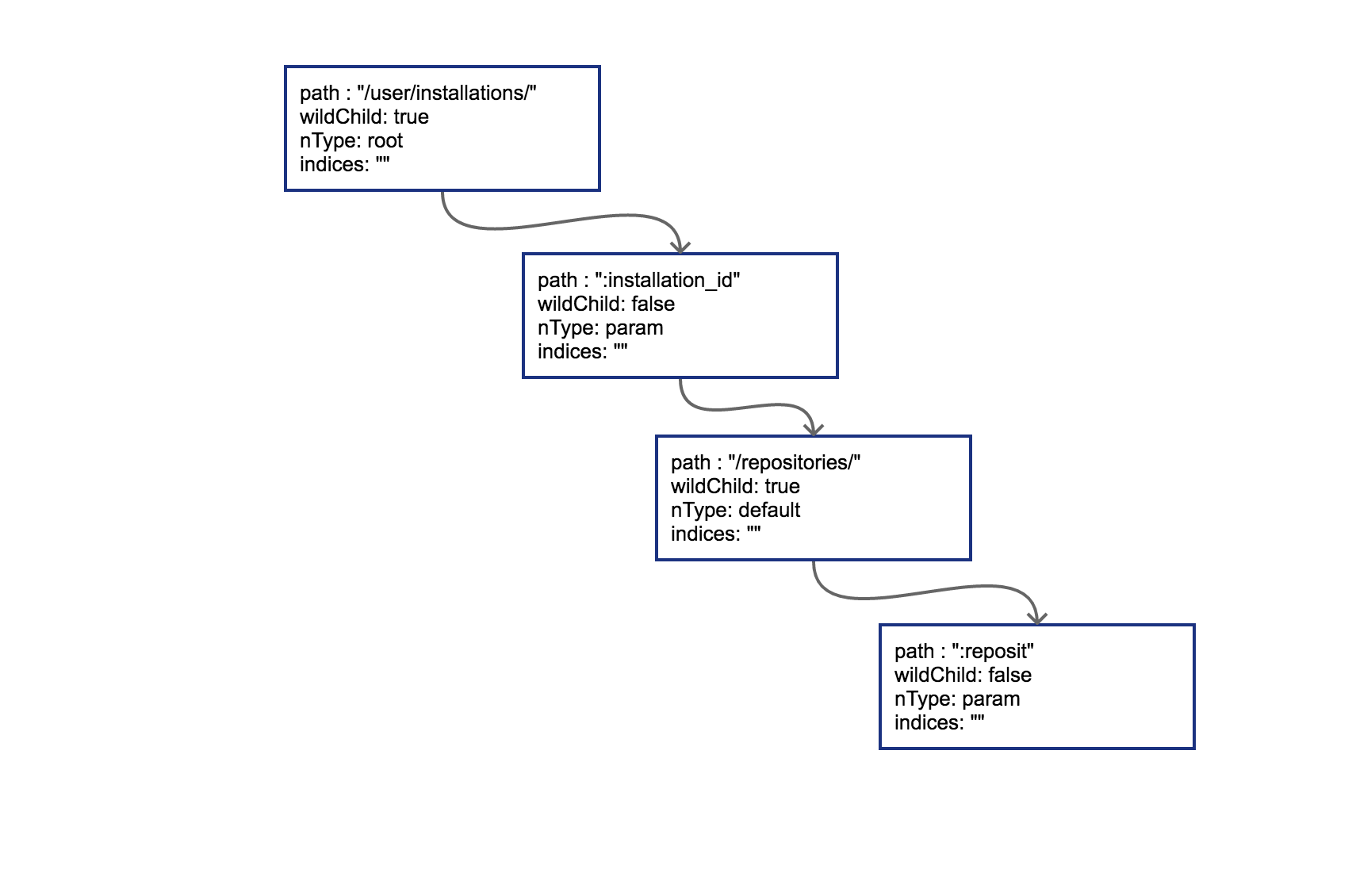
简单来讲,某个方法第一次插入的路由就会导致对应字典树的根节点被创建,我们按顺序,先是一个 PUT:
r := httprouter.New()
r.PUT("/user/installations/:installation_id/repositories/:reposit", Hello)
这样 PUT 对应的根节点就会被创建出来。把这棵 PUT 的树画出来:
图为插入路由之后的压缩字典树
radix 的节点类型为 *httprouter.node,为了说明方便,我们留下了目前关心的几个字段:
path: 当前节点对应的路径中的字符串
wildChild: 子节点是否为参数节点,即 wildcard node,或者说 :id 这种类型的节点
nType: 当前节点类型,有四个枚举值: 分别为 static/root/param/catchAll。
static // 非根节点的普通字符串节点
root // 根节点
param // 参数节点,例如 :id
catchAll // 通配符节点,例如 *anyway
indices:子节点索引,当子节点为非参数类型,即本节点的 wildChild 为 false 时,会将每个子节点的首字母放在该索引数组。说是数组,实际上是个 string。
当然,PUT 路由只有唯一的一条路径。接下来,我们以后续的多条 GET 路径为例,讲解子节点的插入过程
2.2.4 子节点的插入
当插入 GET /marketplace_listing/plans 时,类似前面 PUT 的过程,GET 树的结构如 图 5-4:

图为插入第一个节点的压缩字典树
因为第一个路由没有参数,path 都被存储到根节点上了。所以只有一个节点。
然后插入 GET /marketplace_listing/plans/:id/accounts,新的路径与之前的路径有共同的前缀,且可以直接在之前叶子节点后进行插入,那么结果也很简单,插入后的树结构见 图 5-5:
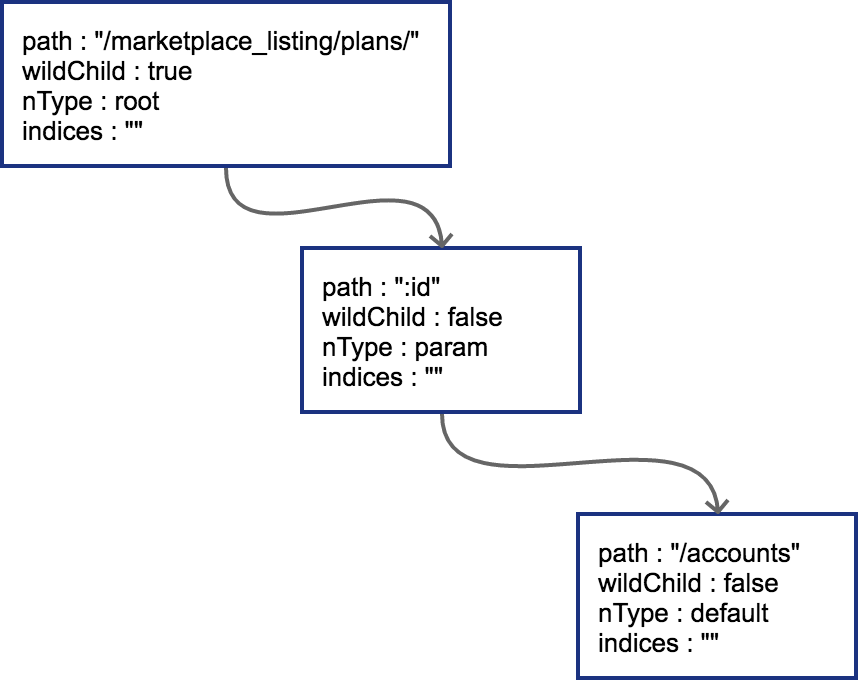
图为插入第二个节点的压缩字典树
由于 :id 这个节点只有一个字符串的普通子节点,所以 indices 还依然不需要处理。
上面这种情况比较简单,新的路由可以直接作为原路由的子节点进行插入。实际情况不会这么美好。
2.2.5 边分裂
接下来我们插入 GET /search,这时会导致树的边分裂,见 图 5-6。
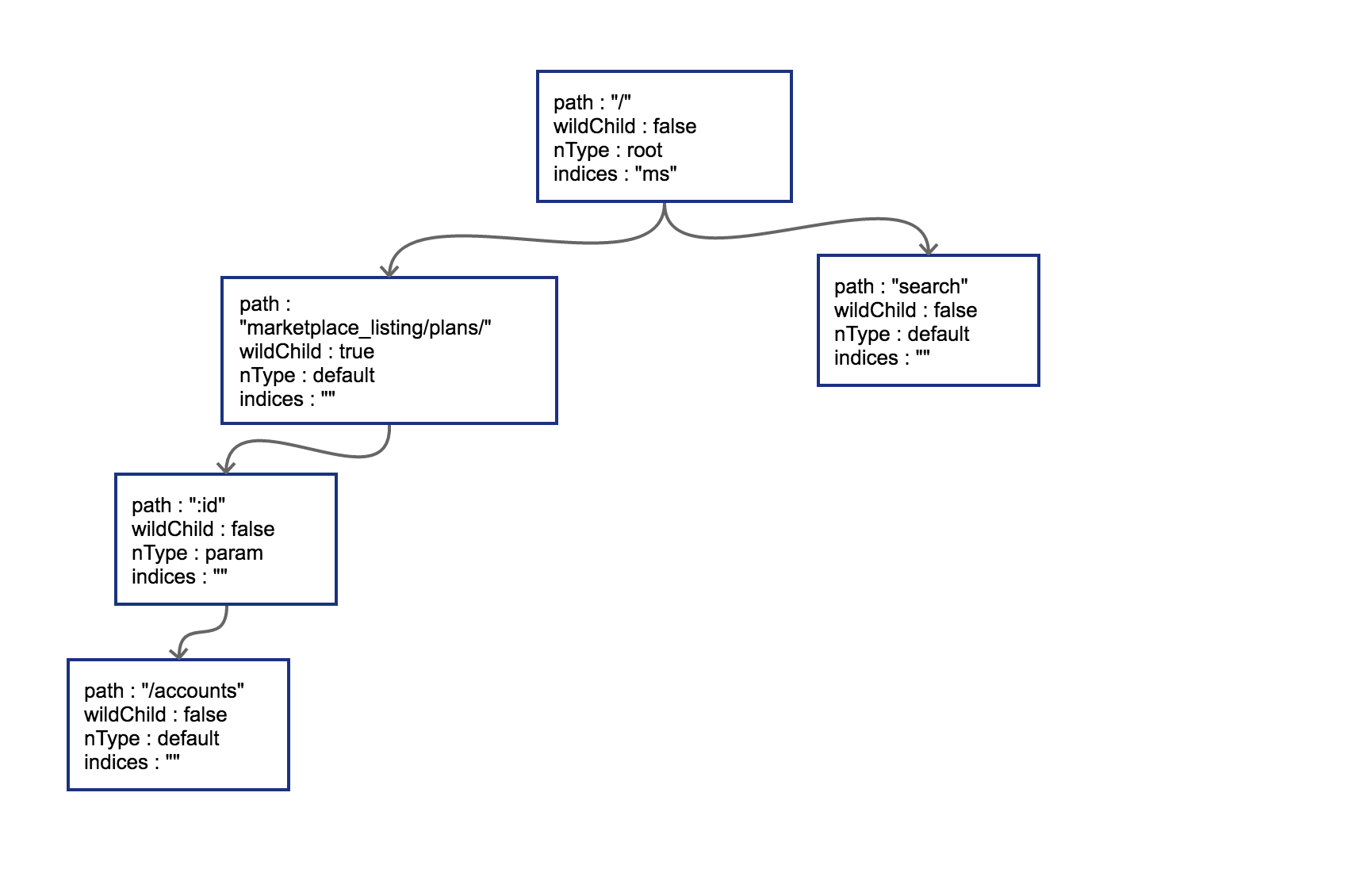
图为插入第三个节点,导致边分裂
原有路径和新的路径在初始的 / 位置发生分裂,这样需要把原有的 root 节点内容下移,再将新路由 search 同样作为子节点挂在 root 节点之下。这时候因为子节点出现多个,root 节点的 indices 提供子节点索引,这时候该字段就需要派上用场了。”ms” 代表子节点的首字母分别为 m(marketplace)和 s(search)。我们一口作气,把 GET /status 和 GET /support 也插入到树中。这时候会导致在 search 节点上再次发生分裂,最终结果见图
插入所有路由后的压缩字典树

2.2.6 子节点冲突处理
在路由本身只有字符串的情况下,不会发生任何冲突。只有当路由中含有 wildcard(类似 :id)或者 catchAll 的情况下才可能冲突。这一点在前面已经提到了。
子节点的冲突处理很简单,分几种情况:
-
在插入 wildcard 节点时,父节点的 children 数组非空且 wildChild 被设置为 false。例如:
GET /user/getAll和GET /user/:id/getAddr,或者GET /user/*aaa和GET /user/:id。解释:就是
GET /user/:id/getAddr和GET /user/getAll有相同的前缀, 如果在已经有getAll的情况下,插入:id让他panic 就行。 - 在插入 wildcard 节点时,父节点的 children 数组非空且 wildChild 被设置为 true,但该父节点的 wildcard 子节点要插入的 wildcard 名字不一样。例如:
GET /user/:id/info和GET /user/:name/info。 - 在插入 catchAll 节点时,父节点的 children 非空。例如:
GET /src/abc和GET /src/*filename,或者GET /src/:id和GET /src/*filename。 - 在插入 static 节点时,父节点的 wildChild 字段被设置为 true。
- 在插入 static 节点时,父节点的 children 非空,且子节点 nType 为 catchAll。
只要发生冲突,都会在初始化的时候 panic。例如,在插入我们臆想的路由 GET /marketplace_listing/plans/ohyes 时,出现第 4 种冲突情况:它的父节点 marketplace_listing/plans/ 的 wildChild 字段为 true。
2.2.2 树(随便写了个三叉树)
因为写到这里的时候发现自己对于树并不是很熟,所以就写了练习补了一下……
package structural
import (
"errors"
"fmt"
)
//第一版写的(有点问题)
type TreeNode struct {
Content string
SonNodes []*TreeNode
IsNilNode bool
IsEnd bool
// 个人觉得设置空节点标志更加的方便
// 当一个节点的儿子节点都是空节点时,意味着这个节点是叶子节点
// 当一个节点本身是空节点的时候,意味他在字典树里面占据了位置,却没有装东西,看起来就像不存在一样
}
func NewTreeNode(content string) *TreeNode {
t := &TreeNode{
Content: content,
// 限制一次最多可以有几个子节点
// 这里我们限制为三叉树
// 只有在明确知道树木是几叉树的情况下,我给一组数据
//(给定的数据是按照约定的顺序规则以切片的形式给出给出『有点像加密与解密』,然后为在拿到这组切片,按照约定的方式,把他们按照想要的格式存储与关联起来『把一个节点作为另外一个儿子节点的过程就是关联』)
SonNodes: []*TreeNode{
nil,
nil,
nil,
},
}
if content == "" {
t.IsNilNode = true
t.IsEnd = true
} else {
t.IsNilNode = false
}
return t
}
func (t *TreeNode) AddSonNodes(nodes []*TreeNode) error {
if t.IsNilNode {
return nil
} else {
t.SonNodes = append([]*TreeNode{}, nodes...)
return nil
}
}
// Root 节点不存储任何内容
type DictionaryTree struct {
Root *Root
NodeNum int
}
// 表明根节点类型,对根节点类型进行限制
type Root struct {
SonNodes *TreeNode
}
func NewRootNode() *Root {
return &Root{}
}
func (r *Root) AddSonNodes(nodes *TreeNode) {
r.SonNodes = nodes
}
func NewDictionaryTree(slice []string) *DictionaryTree {
d := &DictionaryTree{}
d.Root = NewRootNode()
if len(slice) < 3 {
return d
}
nodeptrSile := []*TreeNode{}
for i := 0; i < len(slice); i++ {
nodeptrSile = append(nodeptrSile, NewTreeNode(slice[i]))
}
d.Root.AddSonNodes(nodeptrSile[0])
layers := Getlayers(len(nodeptrSile), 3)
fmt.Printf("layers is %d\n", layers)
for i := 0; i < len(nodeptrSile); i++ {
n := []*TreeNode{nil, nil, nil}
if (i*3 + 1) <= len(nodeptrSile)-1 {
n[0] = nodeptrSile[i*3+1]
}
if (i*3 + 2) <= len(nodeptrSile)-1 {
n[1] = nodeptrSile[i*3+2]
}
if (i*3 + 3) <= len(nodeptrSile)-1 {
n[2] = nodeptrSile[i*3+3]
}
nodeptrSile[i].AddSonNodes(n)
if (nodeptrSile[i].SonNodes[0] == nil) && (nodeptrSile[i].SonNodes[1] == nil) && (nodeptrSile[i].SonNodes[2] == nil) {
nodeptrSile[i].IsEnd = true
}
}
d.NodeNum = len(slice)
return d
}
func Getlayers(nodesNum int, ratio int) int {
if ratio <= 0 {
return 0
}
i := 1
num := 1
for num < nodesNum {
num = num + i*ratio
i = i + 1
}
return i - 1
}
func (d *DictionaryTree) TraverseDictionaryTree() []string {
nodes := []*TreeNode{}
nodes = append(nodes, d.Root.SonNodes)
for i := 0; i < len(nodes); i++ {
if nodes[i].IsEnd {
continue
}
if nodes[i].IsNilNode {
continue
}
nodes = append(nodes, nodes[i].SonNodes...)
}
result := []string{}
for _, v := range nodes {
result = append(result, v.Content)
}
return result
}
func InterfaceToInt(i interface{}) (int, error) {
v, ok := i.(int)
if ok {
return v, nil
} else {
return 0, errors.New("interface type inputed can not be covered to int type")
}
}
func InterfaceToString(i interface{}) (string, error) {
v, ok := i.(string)
if ok {
return v, nil
} else {
return "", errors.New("interface type inputed can not be covered to string type")
}
}
package structural
import (
"fmt"
"testing"
)
// 第一版的测试(有点问题)
type Datas struct {
input []string
want []string
}
func TestTree(t *testing.T) {
input := []string{
"b",
"a", "i", "",
"g", "n", "t",
"g", "l", "t",
}
// 3 9 27
// 3n+3 3n+4 3n+5
datas := Datas{
input: input,
}
d := NewDictionaryTree(datas.input)
want := d.TraverseDictionaryTree()
fmt.Println("input:", datas.input)
fmt.Println("want:", want)
for k, v := range datas.input {
t.Run("test"+v, func(t *testing.T) {
if v != want[k] {
t.Errorf("get:%s ,want:%s", want[k], v)
}
})
}
}
package structural
import (
"errors"
"fmt"
"math"
)
// 第二版(正确)
type TreeNode struct {
Content string
SonNodes []*TreeNode
IsNilNode bool
IsEnd bool
// 个人觉得设置空节点标志更加的方便
// 当一个节点的儿子节点都是空节点时,意味着这个节点是叶子节点
// 当一个节点本身是空节点的时候,意味他在字典树里面占据了位置,却没有装东西,看起来就像不存在一样
}
func NewTreeNode(content string) *TreeNode {
t := &TreeNode{
Content: content,
// 限制一次最多可以有几个子节点
// 这里我们限制为三叉树
// 只有在明确知道树木是几叉树的情况下,我给一组数据
//(给定的数据是按照约定的顺序规则以切片的形式给出给出『有点像加密与解密』,然后为在拿到这组切片,按照约定的方式,把他们按照想要的格式存储与关联起来『把一个节点作为另外一个儿子节点的过程就是关联』)
SonNodes: []*TreeNode{},
}
if content == "" {
t.IsNilNode = true
// 只有最后一层才是
} else {
t.IsNilNode = false
}
return t
}
func (t *TreeNode) AddSonNodes(nodes []*TreeNode) error {
// 是空节点但是不是叶子节点
if t.IsNilNode && !t.IsEnd {
t.SonNodes = append([]*TreeNode{}, []*TreeNode{
// 不是nil,而是
NewTreeNode(""),
NewTreeNode(""),
NewTreeNode(""),
}...)
}
// 每一个新建的节点最开始都是把它当作叶子节点
if t.IsNilNode {
t.SonNodes = append([]*TreeNode{}, nodes...)
return nil
} else {
t.SonNodes = append([]*TreeNode{}, nodes...)
return nil
}
}
// Root 节点不存储任何内容
type DictionaryTree struct {
Root *Root
NodeNum int
}
// 表明根节点类型,对根节点类型进行限制
type Root struct {
SonNodes []*TreeNode
}
func NewRootNode() *Root {
return &Root{}
}
func (r *Root) AddSonNodes(nodes []*TreeNode) {
r.SonNodes = append([]*TreeNode{}, nodes...)
}
func NewDictionaryTree(slice []string) *DictionaryTree {
d := &DictionaryTree{}
d.Root = NewRootNode()
if len(slice) < 3 {
return d
}
nodeptrSile := []*TreeNode{}
for i := 0; i < len(slice); i++ {
nodeptrSile = append(nodeptrSile, NewTreeNode(slice[i]))
}
d.Root.AddSonNodes([]*TreeNode{
nodeptrSile[0],
nodeptrSile[1],
nodeptrSile[2],
})
layers := Getlayers(len(nodeptrSile), 3)
fmt.Printf("layers is %d\n", layers)
//算出最后一层的下标
tag := (3 * (1 - math.Pow(3, float64(layers-1)))) / (-2)
fmt.Print("tag:", tag)
for i := 0; i < int(tag); i++ {
var left *TreeNode
var mid *TreeNode
var right *TreeNode
n := []*TreeNode{}
if (i*3 + 3) <= len(nodeptrSile)-1 {
left = nodeptrSile[i*3+3]
n = append(n, left)
//fmt.Print("child node 0 is ", n[0])
}
if (i*3 + 4) <= len(nodeptrSile)-1 {
mid = nodeptrSile[i*3+4]
n = append(n, mid)
//fmt.Print("child node 1 is ", n[1])
}
if (i*3 + 5) <= len(nodeptrSile)-1 {
right = nodeptrSile[i*3+5]
n = append(n, right)
//fmt.Print("child node 1 is ", n[1])
}
nodeptrSile[i].AddSonNodes(n)
}
d.NodeNum = len(slice)
return d
}
func Getlayers(nodesNum int, ratio int) int {
if ratio <= 0 {
return 0
}
i := 1
num := 3
for num < nodesNum {
num = num + i*ratio
i = i + 1
}
return i - 1
}
func (d *DictionaryTree) TraverseDictionaryTree() []string {
nodes := []*TreeNode{}
nodes = append(nodes, d.Root.SonNodes...)
for i := 0; i < len(nodes); i++ {
if nodes[i].IsEnd {
continue
}
// 就算是nil 节点,下面也还是有节点的,为了保证满,才能用下标阿
nodes = append(nodes, nodes[i].SonNodes...)
}
result := []string{}
for _, v := range nodes {
result = append(result, v.Content)
}
return result
}
func InterfaceToInt(i interface{}) (int, error) {
v, ok := i.(int)
if ok {
return v, nil
} else {
return 0, errors.New("interface type inputed can not be covered to int type")
}
}
func InterfaceToString(i interface{}) (string, error) {
v, ok := i.(string)
if ok {
return v, nil
} else {
return "", errors.New("interface type inputed can not be covered to string type")
}
}
package structural
import (
"fmt"
"testing"
)
// 第二版的测试(正确)
type Datas struct {
input []string
want []string
}
func TestTree(t *testing.T) {
input := []string{
"b", "", "",
"a", "i", "",
//保证除了最后一层,其他层都是满的
"", "", "", "", "", "", "",
"g", "n", "t",
"g", "l", "t",
}
// 3 9 27
// 3n+3 3n+4 3n+5
datas := Datas{
input: input,
}
d := NewDictionaryTree(datas.input)
want := d.TraverseDictionaryTree()
fmt.Println("input:", datas.input)
fmt.Println("want:", want)
for k, v := range datas.input {
t.Run("test"+v, func(t *testing.T) {
if v != want[k] {
t.Errorf("get:%s ,want:%s", want[k], v)
}
})
}
}
- 是三叉树,每个节点有三个孩子节点。
- 根节点root 不存储任何数据。
- 除了最后一层外,其他层都是满的,哪怕某个节点,它的三个孩子节点里面只有一个存储着真正的数据,那么其他孩子节点也要占据位置。