Pods, Nodes, Containers, and Clusters
Kubernetes is quickly becoming the new standard for deploying and managing software in the cloud. With all the power Kubernetes provides, however, comes a steep learning curve. As a newcomer, trying to parse the can be overwhelming. There are many different pieces that make up the system, and it can be hard to tell which ones are relevant for your use case. This blog post will provide a simplified view of Kubernetes, but it will attempt to give a high-level overview of the most important components and how they fit together.
First, lets look at how hardware is represented
Kubernetes 正迅速成为在云中部署和管理软件的新标准。然而,Kubernetes 提供的所有功能带来了陡峭的学习曲线。作为一个新手,尝试解析可能会让人不知所措。系统由许多不同的部分组成,很难判断哪些部分与您的用例相关。这篇博文将提供 Kubernetes 的简化视图,但它将尝试对最重要的组件以及它们如何组合在一起进行高级概述。
首先,让我们看看硬件是如何表示的
Nodes
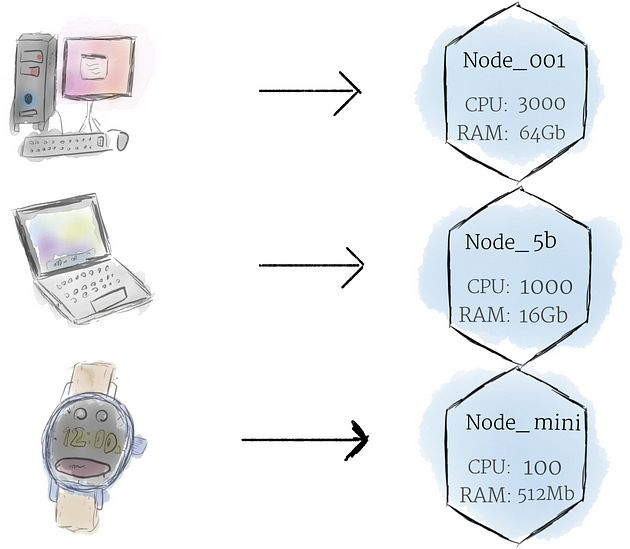
A node is the smallest unit of computing hardware in Kubernetes. It is a representation of a single machine in your cluster. In most production systems, a node will likely be either a physical machine in a datacenter, or virtual machine hosted on a cloud provider like Google Cloud Platform Don’t let conventions limit you, however; in theory, you can make a node out of almost anything
节点 是 Kubernetes 中计算硬件的最小单位。它是集群中单台机器的表示。在大多数生产系统中,节点可能是数据中心中的物理机,或者是托管在像 Google Cloud Platform 这样的云提供商上的虚拟机。但是,不要让约定限制您;理论上,几乎可以用任何东西制作一个节点。
Thinking of a machine as a “node” allows us to insert a layer of abstraction. Now, instead of worrying about the unique characteristics of any individual machine, we can instead simply view each machine as a set of CPU and RAM resources that can be utilized. In this way, any machine can substitute any other machine in a Kubernetes cluster.
将机器视为“节点”允许我们插入一个抽象层。现在,我们不必担心任何单个机器的独特特性,而是可以简单地将每台机器视为一组可以利用的 CPU 和 RAM 资源。这样,任何机器都可以替代 Kubernetes 集群中的任何其他机器。
The Cluster
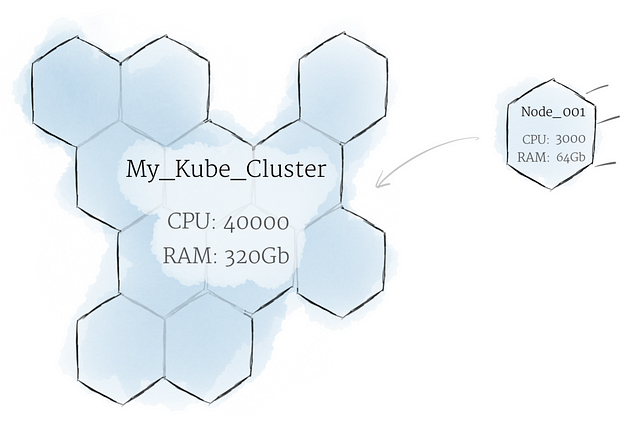
Although working with individual nodes can be useful, it’s not the Kubernetes way. In general, you should think about the cluster as a whole, instead of worrying about the state of individual nodes.
尽管使用单个节点可能很有用,但这不是 Kubernetes 的方式。一般来说,您应该将集群视为一个整体,而不是担心各个节点的状态。
In Kubernetes, nodes pool together their resources to form a more powerful machine. When you deploy programs onto the cluster, it intelligently handles distributing work to the individual nodes for you. If any nodes are added or removed, the cluster will shift around work as necessary. It shouldn’t matter to the program, or the programmer, which individual machines are actually running the code.
在 Kubernetes 中,节点将它们的资源汇集在一起,形成更强大的机器。当您将程序部署到集群上时,它会智能地为您将工作分配到各个节点。如果添加或删除任何节点,集群将根据需要转移工作。对于程序或程序员来说,哪些机器实际运行代码应该无关紧要。
Persistent Volumes
Because programs running on your cluster aren’t guaranteed to run on a specific node, data can’t be saved to any arbitrary place in the file system. If a program tries to save data to a file for later, but is then relocated onto a new node, the file will no longer be where the program expects it to be. For this reason, the traditional local storage associated to each node is treated as a temporary cache to hold programs, but any data saved locally can not be expected to persist.
因为集群上运行的程序不能保证在特定节点上运行,所以数据不能保存到文件系统中的任意位置。如果程序试图将数据保存到文件中以备后用,但随后被重新定位到新节点,则该文件将不再位于程序期望的位置。因此,传统的与每个节点关联的本地存储被视为临时缓存来保存程序,但任何保存在本地的数据都不能指望持久化。
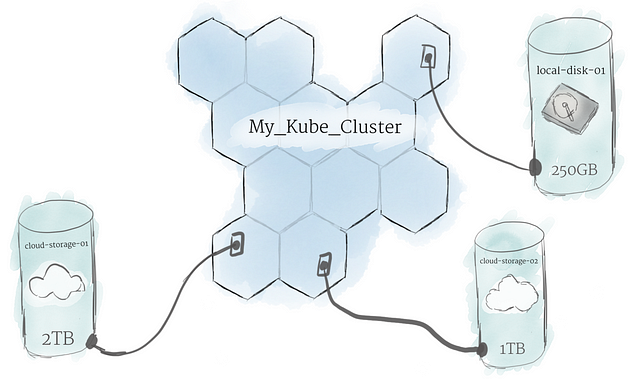
To store data permanently, Kubernetes uses Persistent Volumes While the CPU and RAM resources of all nodes are effectively pooled and managed by the cluster, persistent file storage is not. Instead, local or cloud drives can be attached to the cluster as a Persistent Volume. This can be thought of as plugging an external hard drive in to the cluster. Persistent Volumes provide a file system that can be mounted to the cluster, without being associated with any particular node.
为了永久存储数据,Kubernetes 使用 Persistent Volumes 虽然所有节点的 CPU 和 RAM 资源都由集群有效地汇集和管理,但持久性文件存储却不是。相反,本地或云驱动器可以作为持久卷附加到集群。这可以被认为是将外部硬盘驱动器插入集群。持久卷提供了一个可以挂载到集群的文件系统,而不与任何特定节点相关联。
Software
Containers
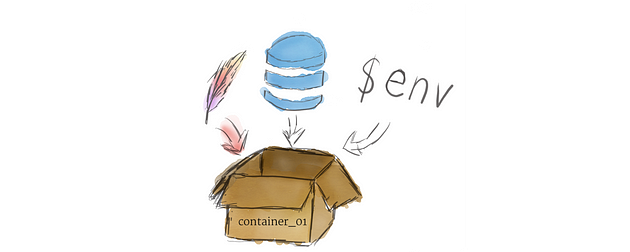
Programs running on Kubernetes are packaged as Linux containers Containers are a widely accepted standard, so there are already many pre-built images that can be deployed on Kubernetes.
在 Kubernetes 上运行的程序被打包为Linux 容器容器是一种被广泛接受的标准,因此已经有很多预构建的镜像可以部署在 Kubernetes 上。
Containerization allows you to create self-contained Linux execution environments. Any program and all its dependencies can be bundled up into a single file and then shared on the internet. Anyone can download the container and deploy it on their infrastructure with very little setup required.
容器化允许您创建自包含的 Linux 执行环境。任何程序及其所有依赖项都可以捆绑到一个文件中,然后在 Internet 上共享。任何人都可以下载容器并将其部署在他们的基础设施上,只需很少的设置。
Multiple programs can be added into a single container, but you should limit yourself to one process per container if at all possible. It’s better to have many small containers than one large one. If each container has a tight focus, updates are easier to deploy and issues are easier to diagnose.
可以将多个程序添加到单个容器中,但如果可能的话,您应该将自己限制为每个容器一个进程。拥有多个小容器总比拥有一个大容器好。如果每个容器都有一个紧密的关注点,更新更容易部署,问题也更容易诊断。
Pods

Unlike other systems you may have used in the past, Kubernetes doesn’t run containers directly; instead it wraps one or more containers into a higher-level structure called a pod. Any containers in the same pod will share the same resources and local network. Containers can easily communicate with other containers in the same pod as though they were on the same machine while maintaining a degree of isolation from others.
与您过去可能使用过的其他系统不同,Kubernetes 不直接运行容器。相反,它将一个或多个容器包装到称为 pod 的更高级别的结构中。同一个 pod 中的任何容器都将共享相同的资源和本地网络。容器可以轻松地与同一个 pod 中的其他容器进行通信,就像它们在同一台机器上一样,同时保持与其他容器的一定程度的隔离。
Pods are used as the unit of replication in Kubernetes. If your application becomes too popular and a single pod instance can’t carry the load, Kubernetes can be configured to deploy new replicas of your pod to the cluster as necessary. Even when not under heavy load, it is standard to have multiple copies of a pod running at any time in a production system to allow load balancing and failure resistance.
Pod 被用作 Kubernetes 中的复制单元。如果您的应用程序变得过于流行并且单个 pod 实例无法承载负载,则可以将 Kubernetes 配置为根据需要将您的 pod 的新副本部署到集群中。即使不是在重负载下,在生产系统中随时运行多个 Pod 副本也是标准的,以实现负载平衡和抗故障。
Pods can hold multiple containers, but you should limit yourself when possible. Because pods are scaled up and down as a unit, all containers in a pod must scale together, regardless of their individual needs. This leads to wasted resources and an expensive bill. To resolve this, pods should remain as small as possible, typically holding only a main process and its tightly-coupled helper containers (these helper containers are typically referred to as “side-cars”).
Pod 可以容纳多个容器,但您应该尽可能限制自己。由于 pod 是作为一个单元进行扩展和缩减的,因此 pod 中的所有容器必须一起扩展,无论它们的个人需求如何。这会导致资源浪费和昂贵的账单。为了解决这个问题,pod 应该尽可能小,通常只包含一个主进程及其紧密耦合的辅助容器(这些辅助容器通常称为“side-cars”)。
Deployments
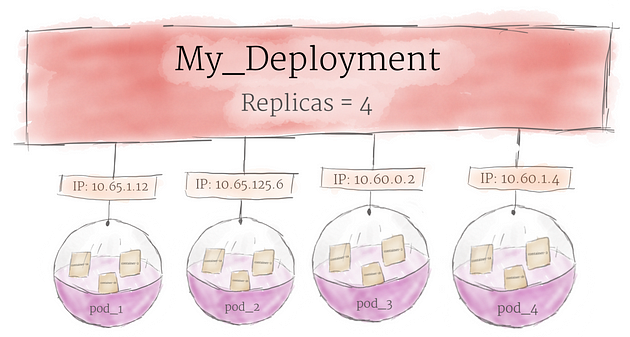
Although pods are the basic unit of computation in Kubernetes, they are not typically directly launched on a cluster. Instead, pods are usually managed by one more layer of abstraction: the deployment
尽管 Pod 是 Kubernetes 中的基本计算单元,但它们通常不会直接在集群上启动。相反,Pod 通常由另一层抽象管理:部署
A deployment’s primary purpose is to declare how many replicas of a pod should be running at a time. When a deployment is added to the cluster, it will automatically spin up the requested number of pods, and then monitor them. If a pod dies, the deployment will automatically re-create it.
部署的主要目的是声明一次应该运行多少个 pod 副本。当部署添加到集群时,它会自动启动请求数量的 pod,然后监控它们。如果 pod 死亡,部署将自动重新创建它。
Using a deployment, you don’t have to deal with pods manually. You can just declare the desired state of the system, and it will be managed for you automatically.
使用部署,您不必手动处理 pod。您只需声明系统所需的状态,它将自动为您管理。
Ingress
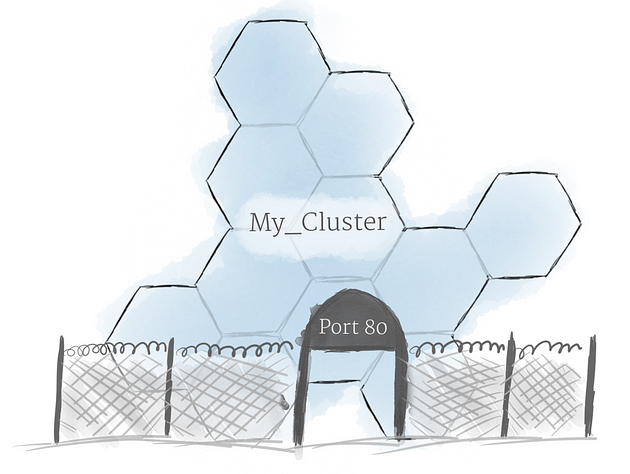
Using the concepts described above, you can create a cluster of nodes, and launch deployments of pods onto the cluster. There is one last problem to solve, however: allowing external traffic to your application.
使用上述概念,您可以创建节点集群,并将 pod 部署到集群上。然而,还有最后一个问题需要解决:允许外部流量进入您的应用程序。
By default, Kubernetes provides isolation between pods and the outside world. If you want to communicate with a service running in a pod, you have to open up a channel for communication. This is referred to as ingress.
默认情况下,Kubernetes 提供 pod 和外部世界之间的隔离。如果要与运行在 pod 中的服务进行通信,则必须打开通信通道。这被称为入口。
There are multiple ways to add ingress to your cluster. The most common ways are by adding either an Ingress controller, or a LoadBalancer. The exact tradeoffs between these two options are out of scope for this post, but you must be aware that ingress is something you need to handle before you can experiment with Kubernetes.
有多种方法可以向集群添加入口。最常见的方法是添加Ingress控制器或LoadBalancer。这两个选项之间的确切权衡超出了本文的范围,但您必须意识到,在您尝试 Kubernetes 之前,您需要处理入口。